Unloading and loading a ClassiX® database
2.1 Call parameters of the programme CXUOSR.EXE (Unloading)
2.2 Call parameters for CXCOSR.EXE (checksum calculation)
2.3 Call parameters of the programme CXLOSR.EXE (load)
3. clustering
5. cross-reference of the objects
1. objectives and procedure
The database is written to sequential files in ASCII format (DATABASE.DMP, FREEOBJ1.DMP, ...), which are in principle also readable for humans. They contain all information about the objects in the database, which is necessary to reconstruct these objects in a new database with the same data and to reconstruct all relations between the objects. Thereby the distribution of the objects to sub-databases, segments and clusters can be changed - this is usually the aim of such an operation.
Unload - Load is also an alternative to the schema evolution provided by ObjectStore (conversion of the database to a new schema, i.e. modified class definitions). During unloading the following information is lost:
- Objects that can no longer be reached (neither via a root entry point collection nor via a relation that starts from at least one other reachable object
- Indices via collections (including the index manager)
Logically deleted objects, however, remain as long as they are still referenced directly or indirectly by an active object.
The overall procedure - including checksum generation to ensure logical integrity - comprises four sub-steps:
- Unloading with programme CXUOSR.EXE
In phase 1 all objects in the root entry point collections are unloaded. In phase 2 it is determined for each previously unloaded object whether relations originating from this object refer to an unloaded object, which is then unloaded. Since such objects also undergo the test just mentioned, the procedure is transitive and at the end of phase 2 all objects accessible via any access path are unloaded. For this purpose a hash table of the (database) addresses of all objects already unloaded is required (TMPFILE.DMP). The objects unloaded in phase 1 can be found in file DATABASE.dmp, the objects from phase 2 in files FREEOBJ1.dmp, FREEOBJ2.dmp, ... For the classes CX_BITMAP, CX_COM_OBJECT and CX_MULTIPLE_COM_OBJECT there is another file per object, which contains the data stream of the object.
Phase 3 is optional: here the assignment of the objects in the root entry point collections is saved in the file REP_COLLS.dmp. - Checksum the "old database" with CXCOSR.EXE (parameter -1)
All objects in the database are read segment by segment and evaluated with a checksum. When reading the segments, even inaccessible objects are "seen". With the hashtable, which was built up during unloading, they can be distinguished from accessible objects. - Loading the new database with CXLOSR.EXE
Restoring the database also takes place in two phases. In phase 1 all objects are created and the data fields are assigned the corresponding values. Phase 2 is responsible for the reconstruction of the relationships between the objects. In order to make this possible, a hash table with the database addresses of all objects is created in phase 1 - similar to unloading - but here each entry also contains the database address of the new database: references in the "old database" can thus be translated very quickly into references in the "new database".
The classification of the new objects in the Root-Entrypoint-Colelctions can be controlled by the description in the CLASSIX.INI-File - and thus can be changed compared to the unloaded original database - or can be restored identically by means of the information saved during the unloading in phase 3.
- Checksum of the "new database" with CXCOSR.EXE (parameter -2)
A checksum is calculated for each object in the newly loaded database. Matching the checksum of the "old database" guarantees that the data fields of all objects have been restored correctly. In addition, the number of relations emanating from each object is evaluated, which also controls the recovery of the object relationship.
In case of discrepancies, it is possible to view the objects concerned in both databases.
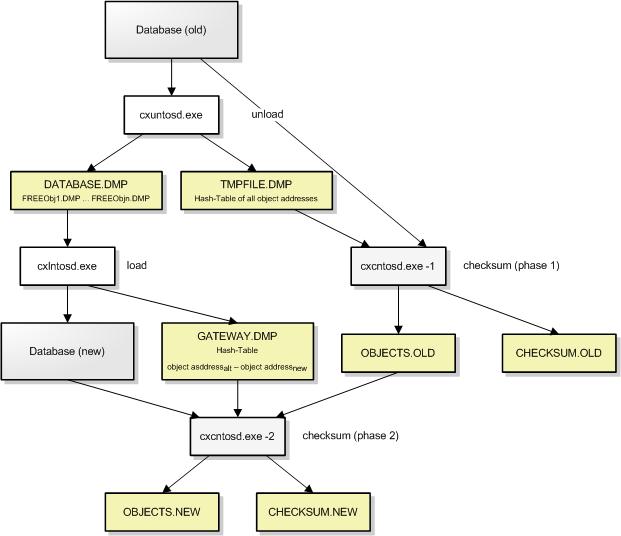
This is the procedure if phase 3 of the unload and load program is not used, i.e. the arrangement of the objects in the root entry point collections is determined by the specifications in CLASSIX.INI. The explicit insertion of the objects in phase 3 guarantees an absolutely identical assignment of the objects to the Root-Entrypoint-Collections (see procedure).
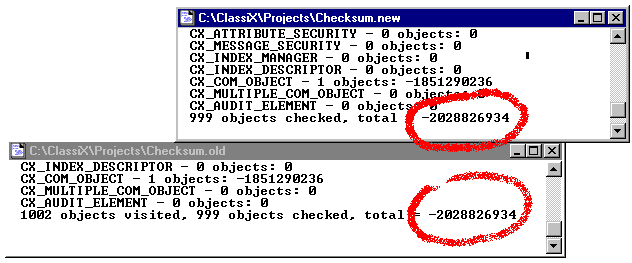
Note: Only if the total checksum in CHECKSUM.OLD and CHECKSUM.NEW are identical, the newly created database can be used instead of the unloaded "old" database.
2. calling up the programmes
All flags can start with / or -. Lower and upper case letters are equivalent. A parameter following a flag can be directly following or separated by blanks; for example:
cxuosr /iTS.INI /h5000000
or
cxuosr -I ts.ini /H 5000000
If successful, the programmes will provide the return code 0.
2.1 Call parameters of the programme CXUOSR.EXE (Unloading)
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /I fileName | Initialisation file | CLASSIX.INI |
| /W fileName | Hash Table | TMPFILE.DMP |
| /D workDir | Working directory in which all other files are written or read from | current directory |
| /Hn | Estimated number n of objects in the database | 47977 |
| /F | Keep Hash-Table in memory (Fast mode) | Hash-Table as file |
| /EparamFile | Hash table on external DCOM servers | Hash-Table as file |
| /1 | only phase 1 | Phase 1 and 2 |
| /2 | only phase 2 | Phase 1 and 2 |
| /3 | Phase 3 | |
| /Cn | Pattern for Clustering | 0xff or value of the environment variables CX_CLUSTERING |
| /Mn | Calculates the memory size of the hash table for n objects. With this you can estimate if a large database can be unloaded with -F or -E. |
The two phases
- Unloading objects from the root entry point collections
- Unloading of all those objects that can only be reached via previously unloaded objects
run automatically one after the other if neither /1 nor /2 is specified.
When unloading, it is determined how the objects are grouped in clusters in the new database to be set up.
Phase 3 collects the information about the arrangement of the objects in the root entry point collections.
Phase 1 is restartable. Prerequisite: Hash table is stored in the memory (parameter /E or /F).
If a class has been completely unloaded after a specified time interval, the hash table is saved as file 'filename.nnn', with nnn = { 001, 002, ... }and a flag is written into the unload file (checkpoint).
At such a point you can put on again: Parameter /R. The resulting parts of the discharge data must be joined together at the end, eliminating superfluous information (data discharged between the last checkpoint and abort) - call with parameter /P.
The following overview shows all other flags relevant for restartability:
| Parameters | Meaning | Standard assumption |
|---|---|---|
| -Vn | Time interval (n in seconds) for restart | -V7200 (i.e. 2 hours) |
| -RclassName,k | Restart after class 'className', k = { 1, 2, ... } is the consecutive number of the restart attempt | |
| -Pfile1{restartInfo1},file2{restartInfo2},...,files,outFile | Copy files together after n-1 restart, eliminate redundant data |
As 'restartInfo' the filename of the rescued hashfile (complete path) has to be entered (see example).
2.2 Call parameters for CXCOSR.EXE (checksum calculation)
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /I fileName | Initialisation file | CLASSIX.INI |
| /W fileName | Hash table (from CXUOSR.exe) | TMPFILE.dmp |
| /G fileName | Hash table (from CXLOSR.exe) | GATEWAY.dmp |
| /D workDir | Working directory in which all other files are written or read from | current directory |
| /1 | Create a checksum of the "old" database | none |
| /2 | Create a checksum of the "new" database | none |
| /U fileName | Hash table from CXUOSR.EXE (only with /1) | TMPFILE.DMP |
| /F | Keep Hash-Table in memory (Fast mode) | as file |
| /EparamFile | Hash table on external DCOM servers | as file |
The checksums for each individual object are written to the file OBJECTS.OLD at /1. If CXCOSR.EXE for the new database is run with /2, the file OBJECTS.NEW is still created, which contains all objects with their checksums. Checksum differences are marked in such a way that the objects concerned can be viewed in both the old and the new database with InstantView® - e.g. with the object inspector - InstantView®-Source: CHECKSUM.CXP. Further functions for analysing objects in the old and new database are provided by the CX_DB_UTILITY object.
The program CXCOSR.EXE provides a further function which is not directly related to the unloading of a database: the creation of an object cross-reference - i.e. an auxiliary database which can be used to determine for each object from which other objects it is referenced
2.3 Call parameters of the programme CXLOSR.EXE (load)
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /I fileName | Initialisation file | CLASSIX.INI |
| /G fileName | Hashfile (gateway from old to new database) | GATEWAY.dmp |
| /D workDir | Working directory in which all other files are written or read from | current directory |
| /H nObjects | Estimated number of objects in the database | 47977 |
| /F | Keep Hash-Table in memory (Fast mode) | as file |
| /EparamFile | Hash table on external DCOM servers | as file |
| /N | DO NOT enter objects in Root-Entrypoint-Colelctions when loading (phase 1), phase 3 is necessary | Insert objects directly into REP-Colls, DO NOT use phase 3 |
| /1 | only phase 1 (loading, creating objects) | Phase 1 and 2 |
| /2 | only phase 2 (reconstructing relations) | Phase 1 and 2 |
| /3 | Phase 3 (insert object in REP collections) | |
| /U | to "add" to already existing database | Database is newly created |
| /batch | in phase 1: create new database(s) (and delete database(s) of the same name) without interactive confirmation | interactive query (must be answered with 'YES') |
| /Mn | Calculates the memory size of the hash table for n objects. This can be used to estimate whether a large database can be loaded with -F. |
Here, too, both phases normally (neither /1 nor /2 specified) run automatically one after the other. CXLOSR.EXE generates a protocol in the file LOAD.LOG
The hash table (GATEWAY.DMP) forms the bridge between the old and new database, i.e. for each object location in the old database the location of the corresponding object in the newly loaded database is known. The table can be kept resident in memory during loading: locally (flag /F) or distributed to external servers (flag /E). A "distributed gateway file" can be combined to one file.
2.4 Example - a batch file
cxuosr -Its.ini
if ERRORLEVEL 1 goto EVENING
cxuosr -3 -Its.ini
if ERRORLEVEL 1 goto EVENING
cxcosr -1 -its.ini
if ERRORLEVEL 1 goto EVENING
cxlosr -its.ini -batch
if ERRORLEVEL 1 goto EVENING
cxlosr -its.ini -3
if ERRORLEVEL 1 goto EVENING
cxcosr -2 -its.ini
echo "Database sucessfully reloaded
break
exit
:EVENING
echo "Reload failed
3. clustering
With ObjectStore the data transfer between the database server and the clients is page-oriented. Therefore the arrangement of the objects in the database determines the performance of the applications to a high degree.
The clustering of the objects can be controlled for
- the object creation with InstantView® commands CreatePersObject, CopyPersObject
- the object creation when unloading/loading a database .
In both cases, clustering can be activated or deactivated in stages.
Under the aspect of clustering, an object is either a master or slave object:
A master object is stored in a segment of the database defined for its class; a cluster may be created for the master object. The information about the segment and any cluster to be created is described in the database layout (file CLASSIX.ODB).
If clustering is completely deactivated, there are only master objects - this is the standard assumption in the ClassiX® system.
The position of a slave object in the database determines another object already stored in the database to which it is connected. The creation of such an object with CreatePersObject, CopyPersObject must be delayed until a relation to an object already existing in the database is established. Therefore the mentioned InstantView® commands first create a (transient) object of the class CX_LAZY_CREATOR.
The procedure for unloading/loading a database is different and is described below.
Before doing so, however, the rules that determine when an object is master and when it is not will be discussed.
The clustering rules have been grouped into categories - according to pragmatic considerations - and, by assigning a bit to each category, a pattern is obtained with which the categories can be switched on and off independently of each other.
This pattern is set with the environment variable CX_CLUSTERING; the default setting is CX_CLUSTERING=0.
The following table shows the categories and the associated rules; in addition to the bit in column 1, a name was assigned in the second column.
Column 3 specifies which classes can appear as slave objects. While for elementary objects (e.g. the base classes CX_DATE, CX_VALUE ...) the class affiliation is sufficient as sole criterion, additional conditions are specified for more complex objects:
- A... means class A and all classes derived from it
- REP_pattern is the bit pattern that determines the classification of the object in the REP-Collection; either specified by the description of the class in CLASSIX.ODB or by explicit specification in CreatePersObject
- Conditions that refer to the master object master are only valid during unloading/loading, with CreatePersObject / CopyPersObject a CX_LAZY_CREATOR is always created
- If an object is created with CreatePersObject, the additional condition REP_pattern = 0 applies to all categories. A transient object CX_LAZY_CREATOR cannot be inserted into a REP collection.
The above rules should not only control the clustering produced by means of delayed object creation (CreateOersObject -> CX_LAZY_CREATOR) but should of course also be effective when unloading/loading a database.
The arrangement of the objects in the new database is already determined when unloading:
If a master object o is unloaded, all objects directly accessible by it via relations (pointers / collections) or are tested according to the above rules, whereby objects o takes on the role of the master. If there are slave objects among the objects, they are unloaded next and marked as belonging to o in the unload file.
When unloading the slave objects the same happens, the or take over the role of the master and all objects accessible by them are tested to see if they can be "clustered" by or. Also these indirectly reached objects get into the cluster belonging to object o. Object o then determines when loading the database how all objects subordinated to it are to be stored.
An object o "asks" all objects referenced by it whether they can be "clustered" by o.
Accordingly, it is important in which order the objects are unloaded.
During unloading, priority numbers (from 0 to 5) are assigned to the classes. In phase 1, all objects are unloaded from the in root entry point collections, with classes with low priority numbers coming first:
| Priority number | |
|---|---|
| 0 | CX_ATOM_TABLE, CX_UNIT_PARAMETER |
| 1 | CX_MULTIPLE_COM_OBJECT |
| 2 | REP_pattern in CLASSIX.ODB > 0 and 0, 1, 4 or 5 does not apply |
| 3 | REP_pattern in CLASSIX.ODB > 0 and 0, 1, 4 or 5 does not apply |
| 4 | CX_DESCRIPTIVE_REF, CX_OVERWRITING_REF |
| 5 | CreatePersObject would create CX_LAZY_CREATOR |
Within the same category the classes are unloaded according to the order of the class descriptions in CLASSIX.ODB, i.e.
also the order of the class statements in CLASSIX.ODB influences the clustering
4. database analysis
If the database contains even a single corrupt object, the unload process will generally terminate with a program error.
Program CXAOSR.EXE can detect such errors in an analysis run and write them to a report file:
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /I fileName | Initialisation file | CLASSIX.INI |
| /D workDir | Working directory in which all other files are written or read from | current directory |
| /A | Analysis of the entire database | none |
| /AsegmentName | Analysis only for the specified segment | none |
| /AsegX-segY | Analysis from segment segX to segY | none |
| /AsegX- | Analysis from segment segX to end | none |
| /A-segY | Analysis (from start) to segment segY (inclusive) | |
| as above, select segments segX, segY with percentage relative to the size of the database segX corresponds to n % of the database size, segY corresponds to m%; condition n < m | none |
| /R | Analysis of all REP Collections | none |
| /R repName | Analysis of the REP collection with the given name | |
| Postprocessing Analyze-Files, only errors referring to corrupt objects are taken over, file for controlling the partial X-reference is generated, 'W' = copied 'WRAPPER' into this file | /Panalyze.lst,analyze2.lst,xObjects.lst |
Example: Distribute analysis runs for a large database on three PCs: cxaosr /A-33%, cxaosr /A34%-66%, cxaosr /A67%-
Note: In a batch file, remember the syntax of the parameters: double the percentage signs, e.g.: cxaosr /A34%%-66%%!
During the analysis (with flag /A...) the virtual function SanityCheck() is called for each object. A return code > 0 signals an error:
Slots
| 1 | Slot: Pointer to data = NULL (or dynamic_cast |
| 2 | Slot: Pointer corrupt (mapping into real memory fails) |
| 3 | Slot - unknown data type (not in the dictionary) |
| 4 | Error in frame: n < g |
| 5 | Error in frame: n < 0 or g < 0 |
| 6 | Error in frame: g > 0 but no slot vector allocated |
| 7 | DeleteSlot has not reset data pointer (to NULL) ... harmless |
| 8 | Slot name = 0 |
| 9 | dynamic slot (see AssignSlot) - slot not in the dictionary |
| 10 | dynamic slot (see AssignSlot) - no relation to defined expression |
| 13 | anonymous slot (see CX_OVERWRITING_REF) - no reference to overwrite expression |
Objects
| 20 - 22 | CXB_MULTIPLE_STRING: Contradiction number - allocated strings |
| 24 | CXB_MULTIPLE_STRING: Partial string cannot be dereferenced |
| 30, 31 | CX_NUMERIC corrupt |
| 32 | Unit corrupt |
| 33 | value 94967254 !!! |
| 41 | CX_DESCRIPTIVE_REF and derived - Pointer to "Wrapper" corrupt (dynamic_cast |
| 42 | CX_DESCRIPTIVE_REF and derived - Pointer to "Wrapper" corrupt (mapping into real memory fails) |
| 50 | CX_EXPANDABLE and derived - classID incorrect |
| 71-73 | CX_SPAN_DATE |
| 80, 81 | CX_PERIODIC_DATE |
| 85, 86 | CX_DATETIME |
| 87-89 | CX_GLOBAL_DATETIME |
| 100-107 | CX_LOCALE ... |
| 391 | CX_FORMULA - Expression contradicts syntax |
| 400 | CX_CONDITIONED_BAG - Chain of CX_FCONDITIONs corrupt (dynamic_cast |
| 401 | CX_CONDITIONED_BAG with "foreign" CX_FCONDITION (fCond->parent != this) |
| 402 | CX_CONDITIONED_BAG - Chain of CX_FCONDITIONs corrupt (mapping into real memory fails) |
| 501 | CX_COM_OBJECT without data (persistentDataStream == NULL) |
| 511 | CX_MULTIPLE_COM_OBJECT contains at least one CX_COM_OBJECT without data |
SanityCheck also calls itself up for members registered in the DDI, provided that the object in question is a property. In case of an error, the original error code + 10000 is returned.
Furthermore, relations to other objects are analysed (function CheckReferences):
| Error | |
| 285 | active object references (logically) deleted object |
| 286 | (logical) deleted object references active object |
| 287 | Reference corrupt (dynamic_cast |
| 316 | Reference corrupt (ObjectStore Exception) |
| 317 | Reference corrupt (undefined exception - caught with catch(...)) |
| 318 | NULL Pointer in Collection |
| 319 | Coll. corrupt (undefinable error, caught with catch(...) |
| 376 | Coll. with cardinality c < 0 or c > 10 000 000 |
| 377 | Coll. - infinite iteration |
| 378 | Coll. with Cardinality by 1 too large |
| 379 | Coll. with too much cardinality |
| 380 | Coll. with too small cardinality |
| 207 | Type of referenced object contradicts DDI / Slot-Dictionary (Pointer) |
| 211 | Type of referenced object contradicts DDI / Slot-Dictionary (Collection) |
| 2001 | ObjectStore Exception already when calling the function SanityCheck() or CheckReferences() |
| 2002 | undefined exception already when calling the function SanityCheck() or CheckReferences() |
Functions of the CX_DB_UTILITY object support an effective analysis of the error log.
5. cross-reference of the objects
Often it would be of interest to know for a certain object o all objects or which reference the object o, i.e. all objects or which have a pointer to o or a collection with o as element.
This information is kept in objects of the class CX_XREF. Building a cross-reference means that for each object exactly one CX_XREF object is created, which refers to all objects that reference the object represented by the CX_XREF object.
It makes sense to keep the CX_XREF objects in a separate physical database - after all, they are only a snapshot that will soon lose its relevance. CX_XREF objects refer to "normal" objects - but not vice versa. The physical sub-database for the cross-reference can therefore be deleted at any time without affecting the "actual" database.
The assignment of an object to "its" CX_XREF object is realised outside the database (in the gateway file).
The function GetObjectsReferringTo() of the object manager returns for an object o passed as parameter a collection of all objects or that reference the object o.
For such an object o, to which no other object or refers, no corresponding object of the class CX_XREF is created, unless you request with flag /O that a CX_XREF object is created for each object in order to find "lonely" objects in the database.
Description of an auxiliary database for the cross reference:
| MetaInfo |
| Database(2, CX_XREFDB) Segment(xrefS, DB(2)) Class(CX_XREF, 51, xref) File(xref, xref, xref) Storage(xref, DB(2), xrefS, EP("xrefL0"(LIST)), CSeg(xrefS), Garbage(xrefG0, xrefS)) |
This description is added to the initialisation file (e.g. classix.ini) as long as you want to work with the cross-reference.
Note:
For performance reasons, the REP collection should be the CX_XREF object of type LIST.
For each object in the source database that is referenced by other objects (most of them) a corresponding object CX_XREF is created. Inserting them into a SET takes more and more time with a growing number of objects.
For large data volumes, a limit value for segment splitting should be specified for the object segment.
Objects of class CX_SLOT_XREF are created in the auxiliary database for the cross-reference of the dynamic data fields. Metainformation for object and slot cross-reference is shown in the following example.
The object-cross-reference is established by using
...
SET CX_XREFDB=myXReferenceDB.cxd
cxgosr -U -I modifiedIniFile.ini -batch
the partial database for auxiliary objects is created.
Afterwards, the cross-reference is built up with CXXOSR.EXE:
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /X n | cross-reference, n estimated number of objects | n = 47977 |
| /X n,objectFile | cross-reference, n estimated number of objects, the object designated in the file is ignored (hide) | n = 47977 |
| /X objectFile | partial cross-reference, i.e. only for the objects specified in the file | |
| /S | form only the cross-reference for dynamic data fields | Cross-reference for objects |
| /B | Cross-references for object and for dynamic data fields in one run | only cross-reference for objects |
| /O | Auxiliary flag for the collection of orphan objects, now for each object of the database an associated CX_XREF object is created | CX_XREF objects are only created for referenced objects |
| /I fileName | (modified) initialisation file | CLASSIX.INI |
| /G fileName | Hashfile (gateway from old to new database) | objects.xrf |
| /F | Keep Hash-Table in memory (Fast mode) | as file |
| /EparamFile | Hash table on external DCOM servers | as file |
| /D workDir | Working directory in which all other files are written or read from | current directory |
The function GetObjectsReferringTo() requires the Gateway file.
Gateway files (parameter /E) distributed to several external DCOM servers can therefore be combined with program CXXOSR.EXE:
| Parameters | Meaning | Standard assumption |
|---|---|---|
| /Cntotal,gatewayFile1,n1,gatewayFile2,n2,... | copies all partial files to GATEWAY.CON |
The correct specification of the partial sizes (n1 + n2 + ... = ntotal) is compared with the specifications in the gatewayFilek files.
Sample batch files for building the complete cross-reference can be found here.
Partial cross-reference:
The construction of the object cross-reference is accelerated if only for a certain set of objects { o1, o2, ... } is determined, which objects or one of the given objects { o1, o2, ... } are referenced. In the parameter /X a file is specified, which
- in the first line contains the estimated number n of objects and optionally the identifier EXCLUDE
- in the following lines the objects are specified by their location in the database
The prime number for the hash file is calculated from the number n - a larger n improves the performance.
EXCLUDE requires that the given objects are not tested as potential speakers. This is useful when repairing corrupt objects in the database: You want to know which objects refer to the "corrupt" objects, but exclude them from the test.
Example:
2000, EXCLUDE <0|284|0|80f230|10000>, <0|284|0|80f350|10000>, <0|284|0|80f470|10000>, <0|284|0|80f590|10000>, <0|284|0|80f7e0|10000>, <0|284|0|80fa20|10000>, <0|284|0|80fb40|10000>, <0|284|0|80fc60|10000>, <0|284|0|80fd80|10000>, <0|284|0|810360|10000>, <0|284|0|8105bc|10000>, <0|284|0|8106ec|10000>, <0|284|0|810800|10000>, <0|284|0|810920|10000>, <0|284|0|810a40|10000>, <0|284|0|810b60|10000>, <0|284|0|810c80|10000>, <0|284|0|810da0|10000>, <0|284|0|810ec0|10000>, <0|284|0|81157c|10000>, <0|284|0|811914|10000>, <0|284|0|811a84|10000>, <0|284|0|812040|10000>, <0|284|0|812268|10000>, <0|284|0|812320|10000>, <0|504|0|7d13cc|10000>
Commas as separators between the elements are optional.
The number of objects per line is unlimited as long as a line length of 512 characters is not exceeded.
Hide certain objects:
Individual objects can also be excluded from the complete cross-reference. This variant is mainly intended as a tool in case you have to deal with corrupt objects in the database. Structure of the file as shown above.
Database analysis and partial cross-reference together form a tool with which logically or physically corrupt or inconsistent objects in a database can be "repaired" (example procedure).
Note: By means of the cross-reference an object in the database can be replaced by another object (function Substitute of the DB-Utility object).
;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}